Federated Learning changes the ML data-sharing game
One of the biggest constraints to machine learning (ML) is the availability of data. What if machine-learning models could learn from private data, such as the personal data on your mobile device or data from collaboration partners’ servers, without sharing the actual data? Welcome to Federated Learning.
Federated Learning is a machine-learning technique that trains an algorithm across multiple decentralised edge devices, or servers holding data samples, without exchanging their data samples (according to Wikipedia). This approach stands in contrast to traditional centralised machine learning techniques where all data samples are uploaded to one server, as well as to more classical decentralised approaches which assume that local data samples are identically distributed.
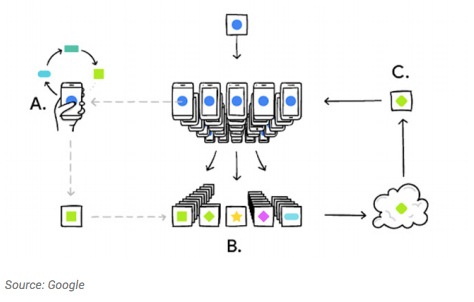
The Google Gboard use-case is often used to explain how Federated Learning works – in this case to improve its predictive typing software. Google initially debuted the tech for its Android keyboard, Gboard, to predict what a user will type next.
As depicted below, Federated Learning allows the Gboard software to improve its ML model without sending raw personal data back to Google.
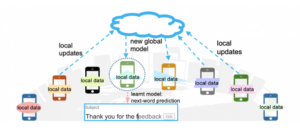
In this case, data stays on your phone instead of being sent to or stored in a central cloud server. Your device downloads the current model, improves it by learning from data on your phone, and then summarises the changes as a small focused update. Only this update to the model is sent to the cloud, using encrypted communication, where it is immediately averaged with other user updates to improve the shared model. All the training data remains on your device, and no individual updates are stored in the cloud.
Another predictive typing use-case is Firefox using Federated Learning to improve its URL search predictions.
Federated learning enables multiple actors to build a common, robust machine learning model without sharing data, thus addressing critical issues such as data privacy, data security, data access rights and access to heterogeneous data. Its applications are spread over a number of industries including defence, healthcare, telecommunications, IoT or pharmaceutics.
Healthcare Applications
Multiple organisations can work together to develop appropriate models without having to transfer sensitive information – such as information about individual patients health records. In a collective effort, the collaborations involved can achieve far more than each one individually if they are to rely solely on the data collected in-house.
In the U.K., Nvidia is partnering with King’s College London and Owkin to create a federated learning platform for the NHS. The Owkin Connect platform running on Nvidia Clara enables algorithms to travel from one hospital to another, training on local datasets. It provides each hospital a blockchain-distributed ledger that captures and traces all data used for model training.
The project is initially connecting four of London’s premier teaching hospitals, offering AI services to accelerate work in areas such as cancer, heart failure and neurodegenerative disease, and will expand to at least 12 U.K. hospitals in 2020.
Autonomous Vehicles
Self-driving connected cars can leverage federated learning to drive safely. For example, instead of avoiding a pothole just based on a predetermined set of algorithms and rules, if a self-driving car utilises the information from all cars that crossed the same pothole in last 1 hour, it will definitely be able to make a better decision in terms of safety and comfort of the passenger.
Federated Learning Platforms
Google has already shared its federated learning platform in the form of Tensorflow Federated. It is in its nascent stage for now but a good learning platform to start with. Upcoming releases will come with new features that will enable users to build an end to end scalable federated machine learning model.
NVIDIA’s latest release of Clara Train SDK, which features Federated Learning (FL), makes this possible with NVIDIA EGX, the edge AI computing platform.
OpenMined is a company that has already started some serious work in this area. Their approach ensures full data protection along with rewards to clients for sharing their learning. I recommend visiting their website if you want to explore more in this field.
Berlin-based XAIN has developed the end-to-end platform for Federated Learning that supports any use case.
Besides the data sharing issue, centralised AI models have the drawbacks of reduced security (increasing difficulty in securely transferring and storing data), incompatibility (industries which require confidentiality and security such as the health sector, insurance, bank, military etc), latency issues (data is not available in real time such as with autonomous vehicles) and the high costs of transferring data.
The great benefit of Federated Learning is that a global AI model can utilise local data, which otherwise would not be available in a simple data-sharing model. Of course all the participants or partners benefit from the global model in their local applications. Federated Leaning also benefits cross-border data models, where, in many cases, legislation requires the data to be stored in a particular jurisdiction, and cross-institutional partnerships.
This increased data diversity is a big win for our machine learning future. One wonders if it will change the power dynamics in value chains, which could be less dependent on individual data monopolies?